


Key Takeaways
From now on, when trying diffusion model, use Equilibrium Matching (EqM) to learn the equilibrium (static) gradient of an implicit energy landscape instead of using Flow Matching learns non-equilibrium velocity field that varies over time
Methods

-
Flow Matching (FM)
-
- is a timestep sampled uniformly between 0 and 1, is Gaussian noise, is a sample from the training set
-
- This can also learn equilibrium dynamics, but doing so will degrades generation quality
-
-
Equilibrium Matching (EqM)
-
- is an interpolation factor sampled uniformly between 0 and 1 but unlike in FM, is implicit and not seen by the model, and is a positive constant that controls the gradient magnitude

-
-
[Optional] Explicit Energy Model
-
- is an explicit energy model that outputs a scalar energy value, there are two ways to construct it from an existing Equilibrium Matching model without having to introduce new parameters:
- Dot Product:
- Squared L2 Norm:
- is an explicit energy model that outputs a scalar energy value, there are two ways to construct it from an existing Equilibrium Matching model without having to introduce new parameters:
-
-
Sampling with Gradient Descent Optimizers
- Gradient Descent Sampling (GD): ;
- Nesterov Accelerated Gradient (NAG-GD): , any other similar optimizer like Adam should also work
- may be learned implicitly () or explicitly ()
- Sampling with Adaptive Compute: Another advantage of gradient-based sampling is that instead of a fixed number of sampling steps, we can allocate adaptive compute per sample by stopping when the gradient norm drops below a certain threshold

Evaluations
Main Results:
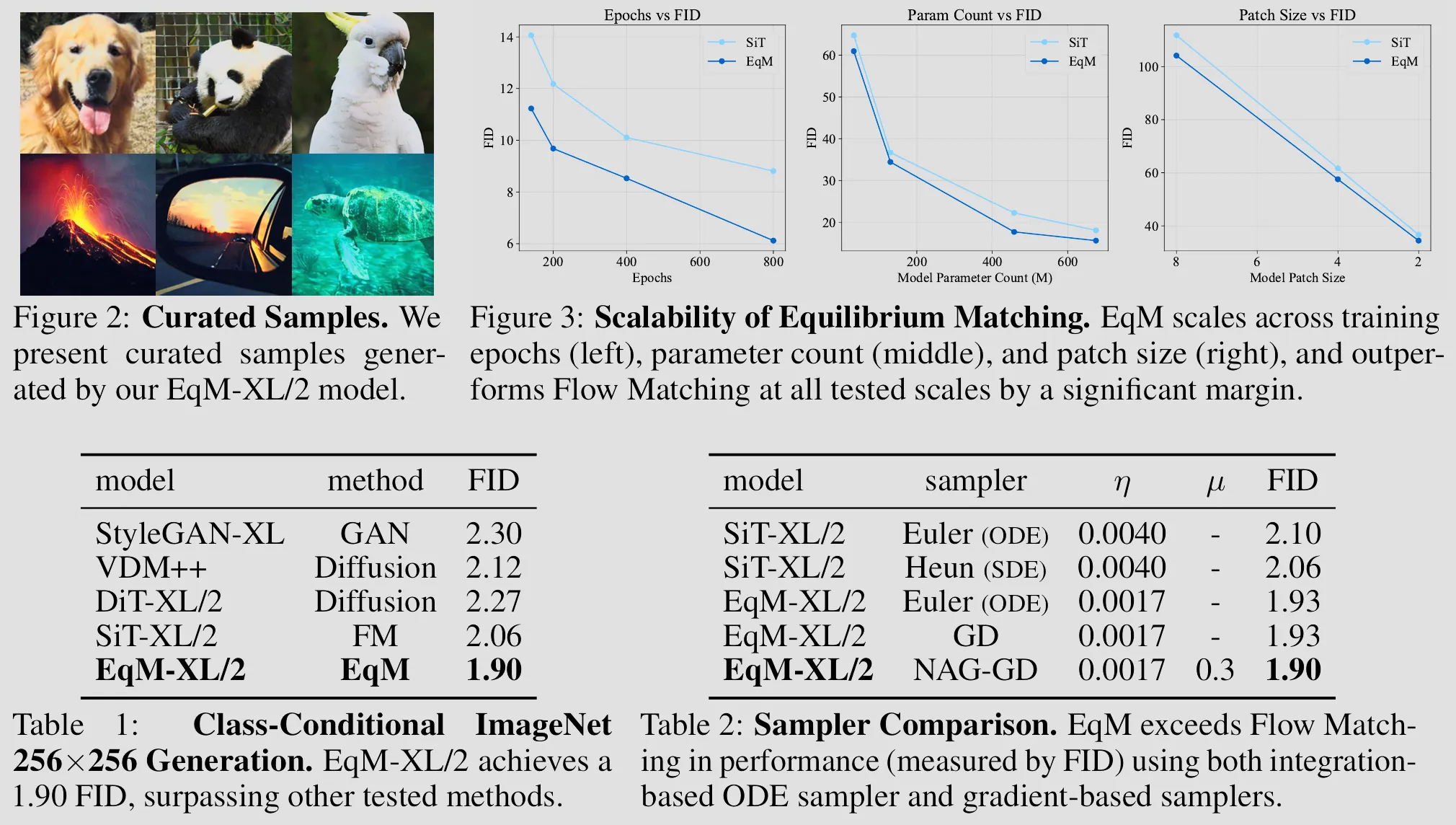
 Ablation Study:
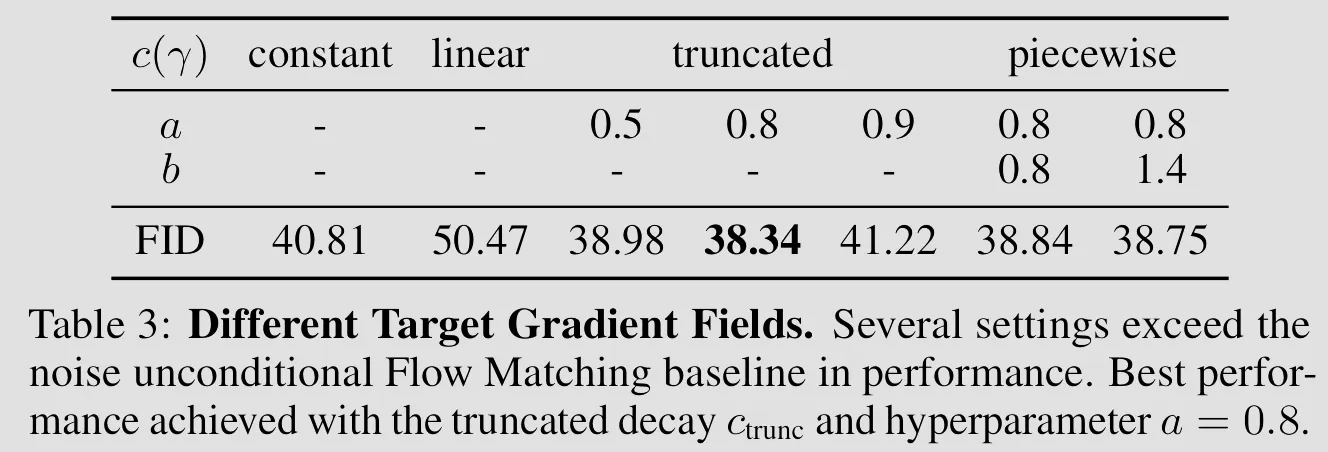
Ablation Study:

Unique properties of Equilibrium Matching that are not supported by traditional diffusion/flow models:
-
Partially Noised Image Denoising: By learning an equilibrium dynamic, Equilibrium Matching can directly start with and denoise a partially noised image.
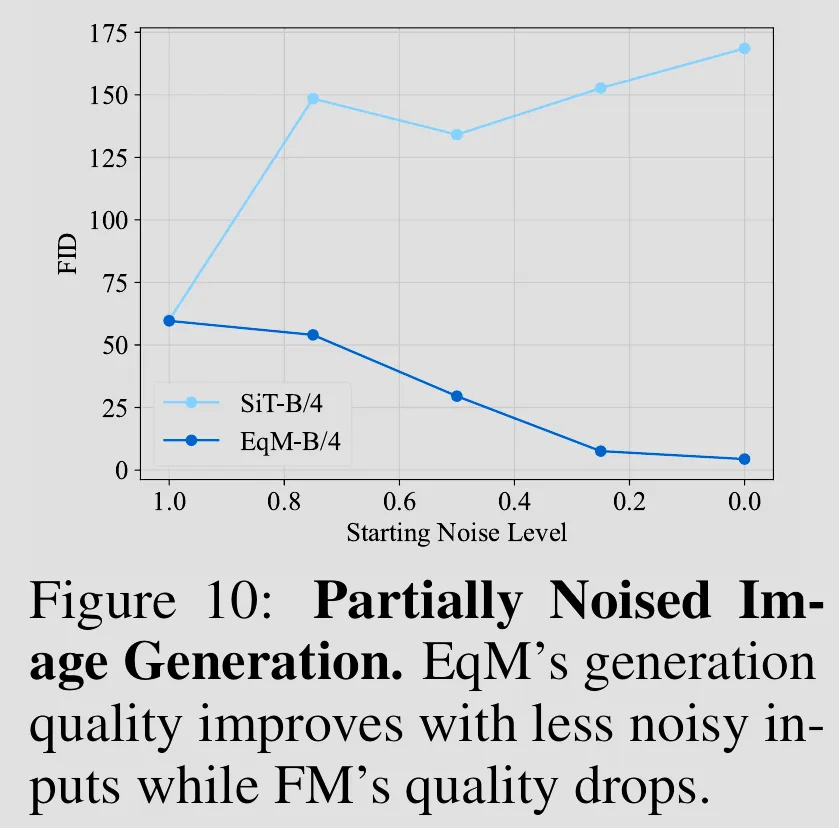
-
Out-of-Distribution Detection: Can perform out-of-distribution (OOD) detection using energy value, in-distribution (ID) samples typically have lower energies than OOD samples.
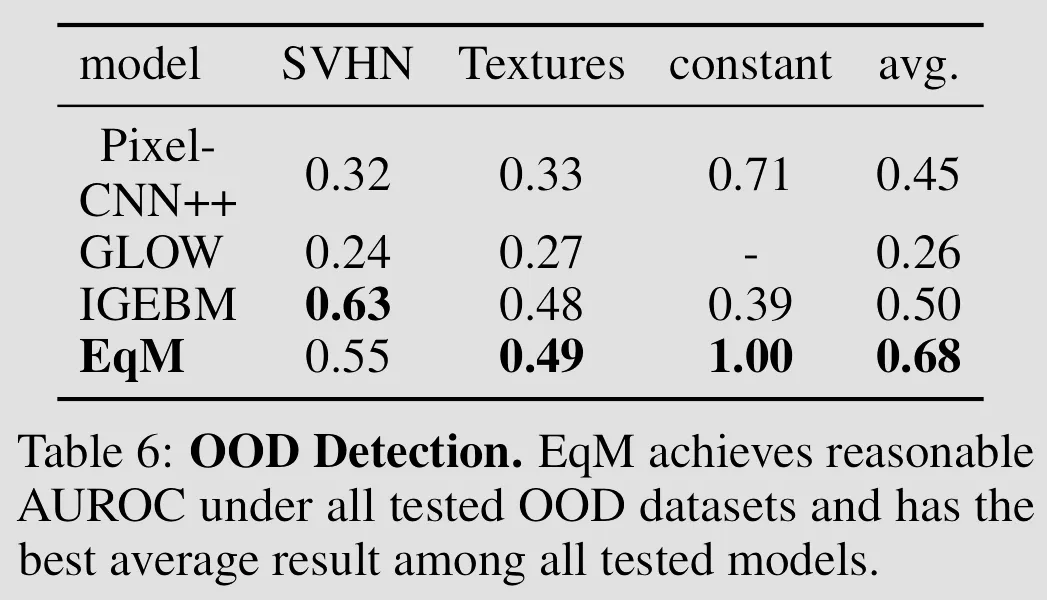
-
Composition: Naturally supports the composition of multiple models by adding energy landscapes together (corresponding to adding the gradients of each model).
